Pytorch中的Autograd
Tensor Basics
在使用Pytorch编写深度学习的代码时,几乎所有模型计算相关的操作都会归结于操作Tensor。其中,Pytorch的自动求导机制(Autograd)是所有神经网络的核心。
在使用autograd对Tensor进行自动求导时,需要用到Tensor自带的一些属性,以下为一个Tensor中通常会记录的属性:
data:Tensor中存储的数据信息。调用.data可以只获取原始Tensor的数据信息,也就是如果原始Tensor的requires_grad=True,那么通过调用.data得到的新Tensor的requires_grad=False。⚠️需要注意的是,在Pytorch推出.detach()方法之后,应该尽量使用该方法,因为其增加了报错信息。由于通过.data得到的新Tensor与原始Tensor共享同一块内存空间,所以在某些情况下(backward的时候)是不安全的,而且还不会报错。requires_grad:将其值设置为True则代表该Tensor需要进行求导,之后对于这个Tensor的所有操作都会被追踪到计算历史记录中。grad:该Tensor的梯度值。⚠️每次在执行backward操作时,都需要将前一时刻的梯度清零,否则梯度值会一直累加造成错误计算。grad_fn:这个就是backward函数,用来计算梯度。同时也指示了梯度函数是哪一种类型。只有非叶子结点(结果结点)才会有grad_fn。is_leaf:简单来讲,我们自己手动创建的Tensor都是叶子结点,而叶子结点之间通过计算得到的中间或最终结果都是结果结点。叶子结点的grad_fn=None。Dynamic Computational Graph
所有需要计算梯度的Tensor与操作它们的函数一起构成了动态计算图(Dynamic Computational Graph),动态计算图展示了从叶子结点到结果结点的完整计算链,沿着这个计算链反向利用链式求导法则即可计算变量的梯度。
下面通过一段代码展示一个简单的计算图:
1 | |
上述代码的计算图如下所示: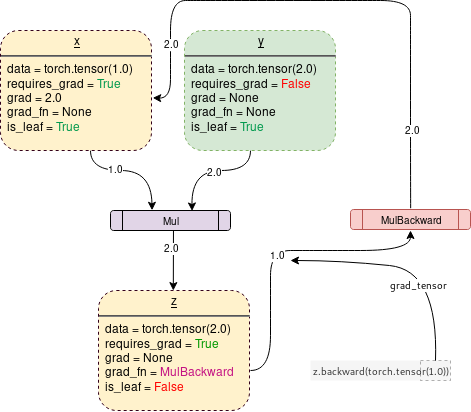
Backward()
当使用torch.autograd.backward()进行梯度计算时,对于得到的结果结点的数据是标量还是非标量要分情况讨论。
结果结点是标量
考虑如下代码:
1 | |
不难看出,上面计算过程的结果z(结果结点)是一个标量,那么可以直接根据链式求导法则计算出所有叶子结点的梯度值。
结果结点非标量
考虑如下代码:
1 | |
可以看到,当结果z是非标量时,直接调用其backward方法会报错。而报错结果的意思就是只有当结果是标量的时候,才会计算并输出梯度值。
为了解决上述问题,先来仔细看一下Pytorch中对于torch.autograd.backward这个方法的定义:
1 | |
tensors:用于计算梯度的Tensor,也就是上面代码中的zgrad_tensors:在结果是非标量时,就需要传入这个参数,本质上就是一个Tensor,形状一般需要和调用该方法的Tensor一致retain_graph:通常在调用完一次backward之后,Pytorch会自动将计算图销毁,如果想要重复调用backward方法,则需要将这个参数设置为Truecreate_graph:当需要计算更高阶的梯度时需要将这个参数设置为True
由此,我们可以看出对于上述代码我们只需要传入一个grad_tensors参数即可,而且参数Tensor的形状要与z的形状一致:传入参数之后,便可以得到关于x的梯度了。这里grad_tensors所做的就是与z进行点积运算(对应元素分别相乘再相加),得到一个标量,最后便可以像之前结果节点为标量时那样利用链式法则来求叶子节点的梯度。1
2
3
4
5
6z.backward(torch.ones_like(z))
print(f'z: {z}')
print(x.grad)
>>> Output
z: tensor([[5., 8.]], grad_fn=<MmBackward0>)
tensor([[3., 7.]])
接下来展示一下上述代码的数学求导过程:
$$
x = (x_1, x_2) = (2, 1)
$$
$$
y = \begin{pmatrix}
y_1 & y_2\
y_3 & y_4
\end{pmatrix} = \begin{pmatrix}
1 & 2\
3 & 4
\end{pmatrix}
$$
$$
z = (x_1, x_2) \begin{pmatrix}
y_1 & y_2\
y_3 & y_4
\end{pmatrix} = (x_1y_1+x_2y_3, x_1y_2+x_2y_4) = (5, 8)
$$
$$
z_{new} = z \cdot (1, 1) = x_1y_1+x_2y_3+x_1y_2+x_2y_4
$$
$$
\frac{\partial z_{new}}{\partial x_1}=y_1+y_2=3, \frac{\partial z_{new}}{\partial x_2}=y_3+y_4=7
$$
关于y的梯度计算过程与上述同理。当明白了这其中的计算原理之后,像上述这种grad_tensors为全1的情况其实是与下面这种写法等价的:1
2
3
4
5
6z.sum().backward()
print(f'z: {z}')
print(x.grad)
>>> Output
z: tensor([[5., 8.]], grad_fn=<MmBackward0>)
tensor([[3., 7.]])
grad_tensors传入的值并不一定非得是全1Tensor,用户可以自己定义其中的每个分量的值。
总结
总的来说,grad_tensors可以简单理解为计算梯度时的权重值。在训练神经网络时,可能会得到非标量的loss张量,其中包含了多个损失项。那么在反向传播计算梯度的时候,如果在backward方法中传入的是全1Tensor就相当于直接将这些损失项加和,也就是权重值全为1。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!